Build a Retrieval Augmented Generation (RAG) App
technique for augmenting LLM knowledge with additional data.
Concepts
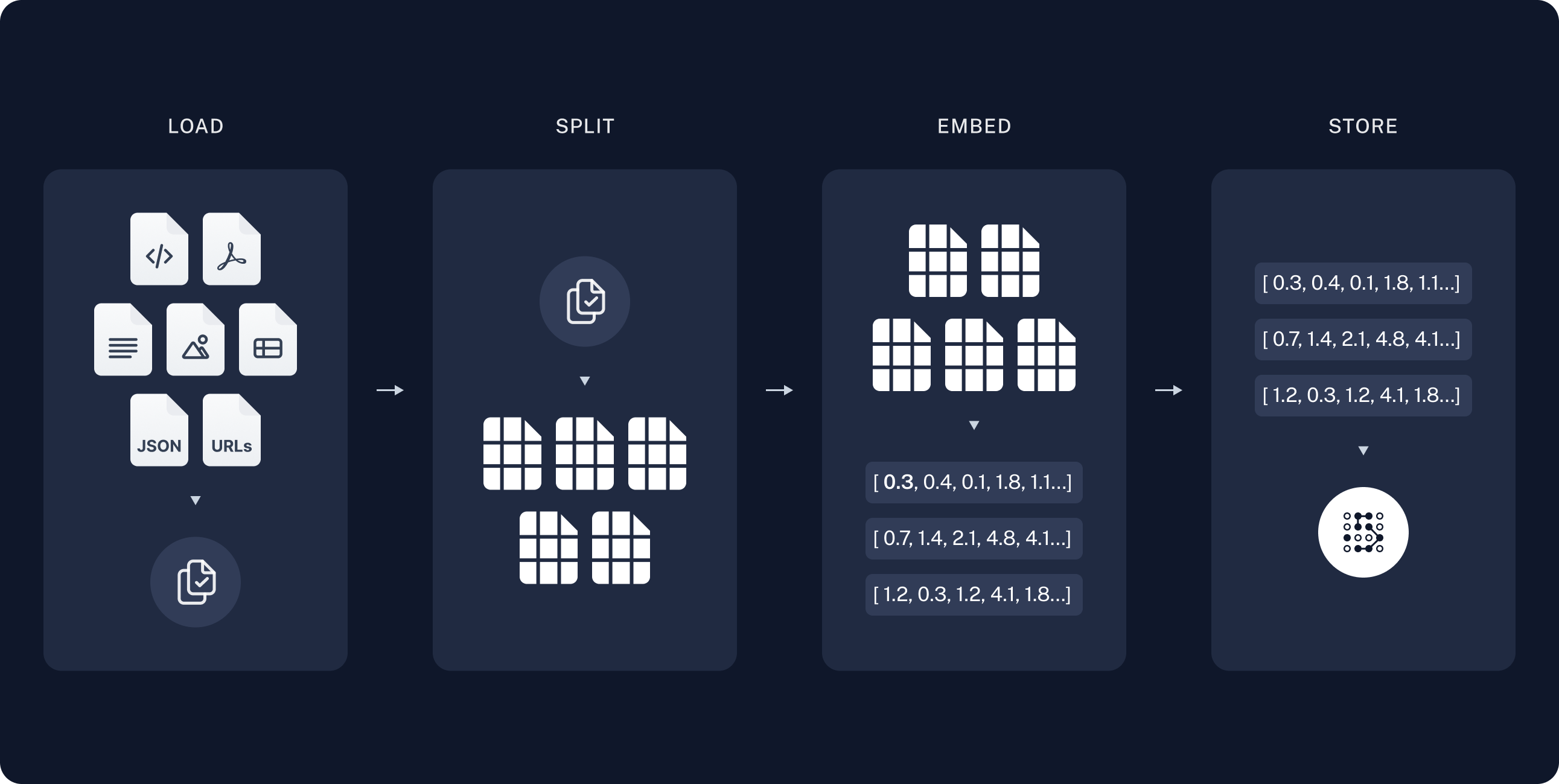
Indexing:
a pipeline for ingesting data from a source and indexing it.
-
Load file using Document Loaders
-
Break large Documents into smaller chunks and embeded into vector
-
Store in VectorStore
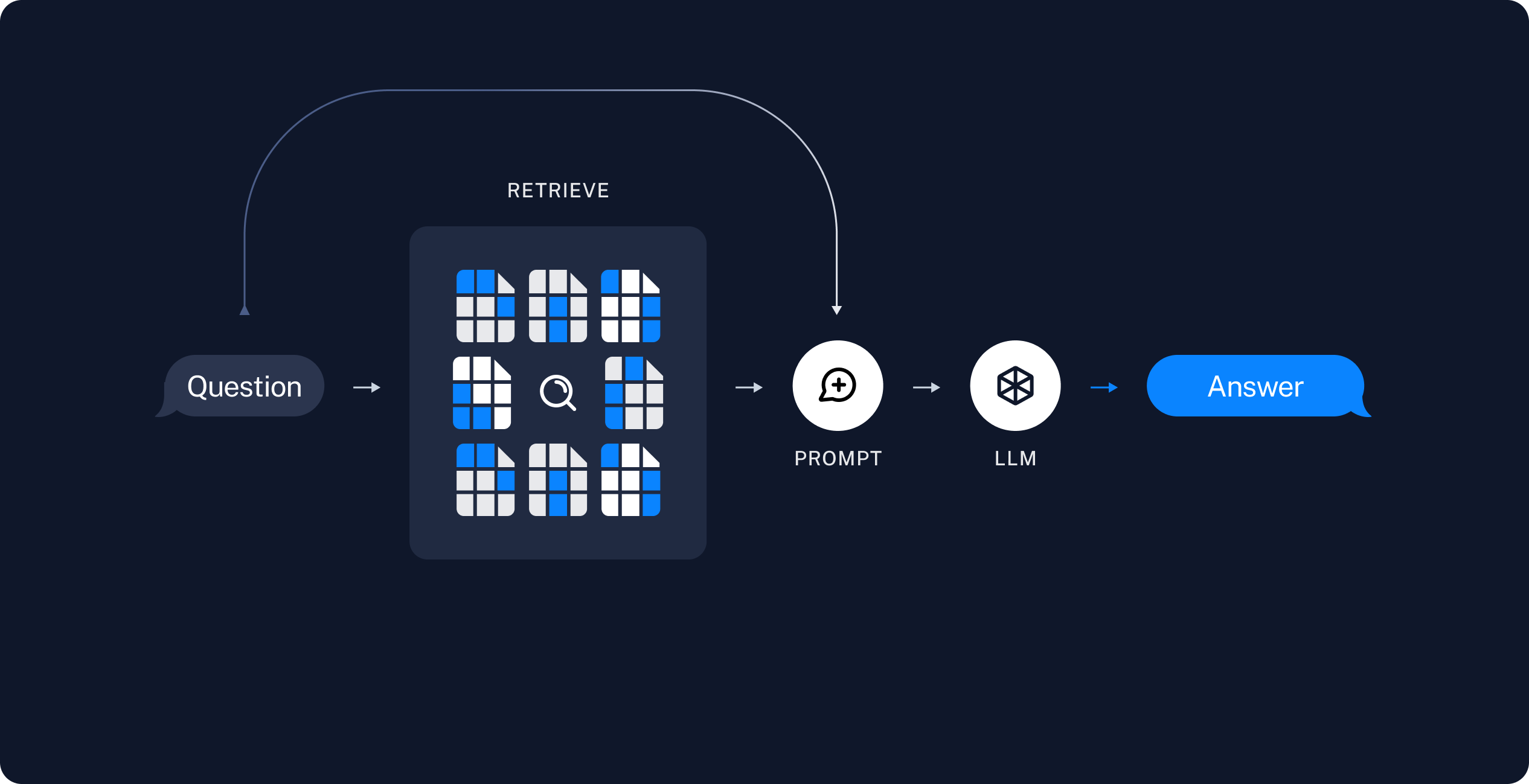
Retrieval and generation:
takes the user query at run time and retrieves the relevant data from the indexnd generation:
-
Retrieve: Retrieve relevant splits from storage usng a Retrieve
-
Generate: produces answer with retrieved data and prompt
Install
For pip
pip install --quiet --upgrade langchain langchain-community langchain-chromaFor conda
conda install langchain langchain-community langchain-chroma -c conda-forgeMoniter the process --- LangSmith
Inspect what exactly is going on indside chain or angent
-
Set env for langchain
Login to get LANGCHAIN_API_KEY
# add follow code to .env LANGCHAIN_TRACING_V2="true" LANGCHAIN_API_KEY="..."
Demo
Install
install langchain-openai
pip install -qU langchain-openaiCode
This is a demo to establish a langchain
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv() # take environment variables from .env.
llm = ChatOpenAI(model="gpt-4o-mini")
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# Split documents and embed into vector
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Chroma.from_documents: Creates a Chroma vectorstore from splits by embedding each
# chunk with OpenAIEmbeddings.
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# using pipeline | send format_docs to retriever
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# incoke the function to solve the problem
rag_chain.invoke("What is Task Decomposition?")
# cleanup
vectorstore.delete_collection()Last updated on